Innovazione
I segreti della similarity, pilastro dei social media e dello shopping online
Michele Barbera è il CEO di SpazioDati, startup dietro Atoka. Questo post è sponsorizzato da:

«Chi si somiglia, si piglia» recita un proverbio italiano a cui alcune scoperte di genetica hanno forse dato un fondamento. Anche noi di SpazioDati ci stiamo occupando di somiglianza; per la precisione, di ciò che in gergo tecnico viene definito similarity, ossia il grado di somiglianza esistente tra due items.
Il concetto di similarity è poliedrico. Immaginiamo di camminare per le corsie di un supermercato con sguardo attento alle persone anziché agli scaffali. In quel contesto possiamo definire due persone “simili” se hanno, appunto, un aspetto simile: ad esempio sono entrambe uomini giovani con i capelli castani, gli occhi azzurri e una statura notevole. Per verificare una tale somiglianza potremmo usare anche altri metodi: ad esempio analizzare le loro carte d’identità, e vedere se sono più o meno sovrapponibili.
Potremmo però accantonare le fisionomie dei vari clienti del supermercato e concentrarci sui carrelli. Per esempio due clienti che acquistano lo stesso tipo di formaggio sardo stagionato, uno shampoo bio per capelli, lime e cetrioli (che quasi di sicuro finiranno in un gin tonic) probabilmente hanno molto a che spartire: sono simili perché hanno gli stessi gusti, e profili d’acquisto che coincidono. Potrebbe però colpirci un assembramento. Ad esempio un gruppo di giovani amiche che fanno la spesa infilando a turno prodotti nello stesso carrello. Probabilmente le troveremo simili l’una all’altra, se non altro perché si muovono assieme e sono collegate da chiare e strette relazioni sociali. Come recita un altro proverbio italiano, «dimmi con chi vai e ti dirò chi sei». E così, alla luce fredda dei neon del supermercato, si può dunque fare esperienza di tre diversi tipi di similarità:
1. una anagrafica (l’aspetto)
2. una di comportamento (il carrello)
3. una di relazioni (il gruppo).
Nella new economy, questi tre punti di vista sono sempre più utilizzati dalle piattaforme online per fornirci delle raccomandazioni mentre le visitiamo. Se siamo sul sito di un colosso dello shopping digitale, ad esempio, ci vengono suggeriti prodotti comprati da clienti che in passato hanno fatto le nostre stesse spese (“chi ha acquistato questo prodotto ha anche comprato quest’altra cosa”); in altre parole, si guarda ai “carrelli”. Sui social media, invece, ci vengono suggeriti account seguiti da persone cui siamo connessi o che sono connesse ai nostri stessi account (“popolare nella tua rete”): sfruttano la topologia delle nostre relazioni, dunque, per capire a chi siamo simili. Per l’approccio anagrafico non serve scomodare i titani del web, basta guardare un ragazzo che distribuisce volantini per la promozione di un nuovo locale: cercherà con gli occhi chi assomiglia alla clientela-tipo del locale. Riepilogando con un po’ più di precisione (almeno a livello terminologico) si hanno:
1. la demographic-based similarity
2. il collaborative filtering
3. la network-based similarity.
SpazioDati usa il secondo e terzo tipo di similarity per aiutare gli utenti di Atoka in fase di up-selling e cross-selling (consigliando quali altri prodotti offrire ai loro clienti), ma anche per sostenere l’espansione del loro business sulla base della loro rete sociale. Per esempio: se l’azienda X è riuscita a vendere il suo prodotto Y alle aziende A, B e C, e sia B che C hanno rapporti di lavoro con l’azienda D, è probabile che X possa vendere Y anche a D.
Ma è soprattutto il primo tipo di similarity a essere sfruttato da SpazioDati, per produrre la targeted lead generation. In poche parole, aiutare un’azienda a trovare nuovi clienti simili per dimensione, specializzazione, semantica e via discorrendo alle aziende già in portafoglio. Per comprendere meglio il senso di tutto questo occorre una premessa. Uno dei prodotti di punta di SpazioDati è Atoka, tool di lead generation e sales intelligence che ha tra i suoi obiettivi primari la generazione di lead per l’utente, ossia i nominativi (e i relativi contatti) di possibili clienti rispondenti a determinati requisiti. Nel concreto, oggi chi usa Atoka ottiene liste di lead sulla base di una serie di filtri che è stato lui stesso a impostare.
Supponiamo, ad esempio, che l’utente possieda un’azienda di prototipazione rapida a Roma specializzata nella produzione di pezzi per auto one-off, e che sia alla ricerca di nuovi clienti del settore automotive nella provincia di Milano; potrebbe iniziare, per esempio, combinando un primo parametro geografico di selezione (solo le aziende con sede legale nella provincia di Milano) con un parametro di tipo economico-statistico (solo le aziende con codice ATECO 29.1) e magari anche uno di tipo finanziario (solo le imprese con i ricavi in crescita).
Naturalmente i filtri di cui è munita Atoka sono tanti, e le possibilità di combinazione quasi illimitate. Se volessi usare una metafora, attraverso i filtri si può trasformare una grande rete da pesca a strascico in un arpione ad alta precisione. Il punto però è che al momento è compito dell’utente decidere quali filtri applicare e quali invece tralasciare per creare la propria lead list. Certo, questa fase di affinamento, che i nostri tecnologi chiamano filter refinement, è molto efficace, dato che consente di generare lead calzanti e utili. Tuttavia è suscettibile di miglioramento, grazie appunto alla targeted lead generation.
La targeted lead generation nasce dunque da una domanda assai banale: come si può rendere ancora più facile la vita agli utenti di Atoka per quanto riguarda l’impostazione di filtri? Semplificando, l’idea di fondo è che l’utente possa fornire un suo campione di interesse (ad esempio una lista di aziende che sono già sue clienti) e che un algoritmo ad hoc estragga le caratteristiche-chiave di questo insieme, le “studi” e imposti di conseguenza dei filtri consoni; in questo modo i nuovi lead generati indirizzeranno ad aziende simili a quelle che hanno già acquistato i prodotti o i servizi dell’utente. Ovvio, il campione deve essere abbastanza rappresentativo: banalmente, più ampio è meglio è; con un paio di nominativi, o anche solo poche decine, si ottiene poco o niente.
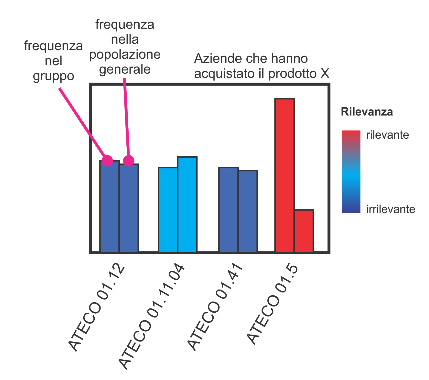
Con “rilevante”, in questo contesto, viene inteso ogni fenomeno che si presenta nel gruppo con una frequenza che devia da quella attesa (ovvero la frequenza che si avrebbe in un gruppo selezionato casualmente dall’insieme di tutte le aziende italiane). Nel grafico sopra, tratto da un’analisi su un gruppo di aziende, si nota che l’ATECO 01.5 viene segnalato come molto rilevante perché è ben più frequente nel campione considerato rispetto alla popolazione generale.
Non cito spesso il pensiero junghiano, ma selezionando i vari filtri per perimetrare il pool di lead l’utente tende a definire una sorta di archetipo di gruppo; va a disegnare, cioè, una sorta di cliente ideale, identificato attraverso le sue caratteristiche più distintive e auspicabili. Nella targeted lead generation è la macchina a definire l’archetipo, e con più efficacia e puntualità dell’operatore umano, dal momento che analizza i valori, li classifica secondo criteri oggettivi e trasforma quelli statisticamente più rilevanti, cioè più distinguenti, in filtro. Oltre a semplificare la vita, la targeted lead generation permette così di scovare caratteristiche che l’utente umano neanche immagina. Aiutandolo a capire meglio una realtà piccola ma per lui importantissima: quella dei suoi clienti, presenti e futuri.
La splendida foto nella cover è “Colonia di fenicotteri al lago Nakuru” di Syllabub, CC BY-SA 3.0 [modificata]. Michele Barbera, autore di quest’articolo, è il CEO di SpazioDati.
{kind=link}
Devi fare login per commentare
Accedi