Innovazione
Come mappare i nuovi distretti industriali del Regno Unito con i dati sul web
Michele Barbera è il CEO di SpazioDati, startup dietro Atoka. Questo post è sponsorizzato da:

Proprio ieri è stato reso pubblico l’annuale rapporto Cerved sulle PMI italiane. Alla presentazione del rapporto c’era anche il sottoscritto, che ha illustrato gli elementi salienti della monografia sulle startup e le imprese innovative in Italia curata da SpazioDati con il nostro partner Cerved. Per realizzare l’analisi noi di SpazioDati abbiamo fatto ricorso a un approccio innovativo, basato sull’uso dei big data e delle metodologie del semantic web. Un approccio già sperimentato con successo lavorando con il governo britannico.
A inizio 2016, infatti, abbiamo realizzato un report per il Department for Business, Innovation and Skills (BIS, un po’ l’equivalente del nostro ministero dello sviluppo economico), insieme a due partner di eccellenza: il National Institute of Economic and Social Research (NIESR) e il City REDI dell’Università di Birmingham. Oggetto del report era un tema che da sempre desta grande interesse qui in Italia: i distretti industriali, uno dei punti di forza della nostra economia (si veda, a questo proposito, l’VIII rapporto annuale di Intesa San Paolo).
Che cosa sia un distretto industriale, lo sappiamo tutti. Per Giacomo Becattini questo tipo di sistemi produttivi localizzati trae la propria vitalità da “una rete complessa e inestricabile di economie e diseconomie esterne, di congiunzioni e connessioni di costo, retaggi storico-culturali che avvolge sia le relazioni interaziendali che quelle più squisitamente personali”. E secondo Michael Porter, per definire un cluster industriale occorrono 3 fattori: la collocazione geografica delle aziende (ad es. la co-location), le relazioni funzionali tra loro, la presenza di collegamenti istituzionali. Io aggiungo una battuta: quando si parla di distretti, occorre tenere sempre a mente il mantra dei mitici agenti immobiliari americani “location location location”!
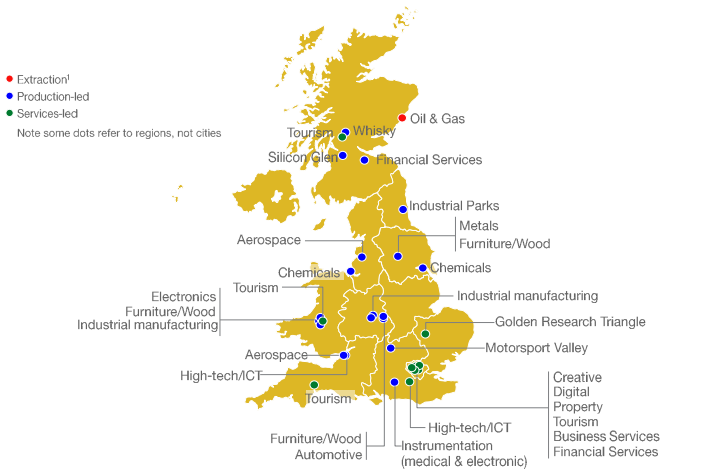
I distretti industriali, ovviamente, esistono anche nel Regno Unito, seppur con le peculiarità proprie di un paese con una storia, una geografia e una struttura economica alquanto diverse dalla nostra. Quello che il BIS ci chiedeva di fare, in particolare, era usare i dati web per analizzare i modelli di raggruppamento geografico e integrazione funzionale in tre settori: la sanità digitale (Digital Health), i servizi finanziari e l’industria di trasformazione. Ossia tre settori capaci di rappresentare, rispettivamente, un settore emergente, un settore dei servizi consolidato (anzi, consolidatissimo) e un settore del manifatturiero caratterizzato dalla presenza di un’organizzazione distrettuale “ufficiale” (la NEPIC, North East of England Process Industry Cluster).
Rispetto alla finanza e all’industria di trasformazione, il settore della sanità digitale è un’industria giovane, meticcia ed ibrida. Che include aziende manifatturiere e di servizi impegnate nello sviluppo o nell’applicazione di nuove tecnologie per e alla sanità. Proprio a causa della sua natura variegata, dunque, è difficile mappare la sanità digitale con i soliti SIC (Standard Industrial Classification), ossia l’equivalente anglosassone dei nostri ATECO. A differenza di quanto accade con gli altri due settori, nella sanità digitale non sono in ballo una manciata di SIC facilmente associabili al settore. E alcuni tipi di SIC includono sia aziende che effettivamente operano nella sanità digitale, sia aziende del tutto estranee al settore.
Qualche esempio: sono nel business della Digital Health sia la startup che fa app per assistere i malati a distanza (e che magari è sotto lo stesso SIC della startup che sviluppa videogiochi per dispositivi mobile), sia l’azienda che realizza macchinari medicali, e che ovviamente ha un SIC diverso da quello della startup; operano nel settore di interesse sia l’ente che organizza corsi di medicina personalizzata, sia la ditta importatrice di wearable devices a scopo sanitario (e che probabilmente nuota nello stesso calderone classificatorio della ditta che importa dal Far East i soliti prodotti elettronici di consumo).
Piccolo inciso: poiché non possono esistere tanti codici SIC e ATECO quante sono le aziende (proprio come una mappa 1:1 non serve a nessuno; ce lo insegna Borges nello stupendo micro-racconto “Del rigor en la ciencia”), è evidente che nei prossimi anni diventerà sempre più evidente e urgente la necessità di andare oltre queste modalità di classificazione. Che continuano a essere molto utili, ma che non possono certo stare al passo con le trasformazioni rapidissime, a velocità quasi vertiginosa, delle economie del XXI secolo.
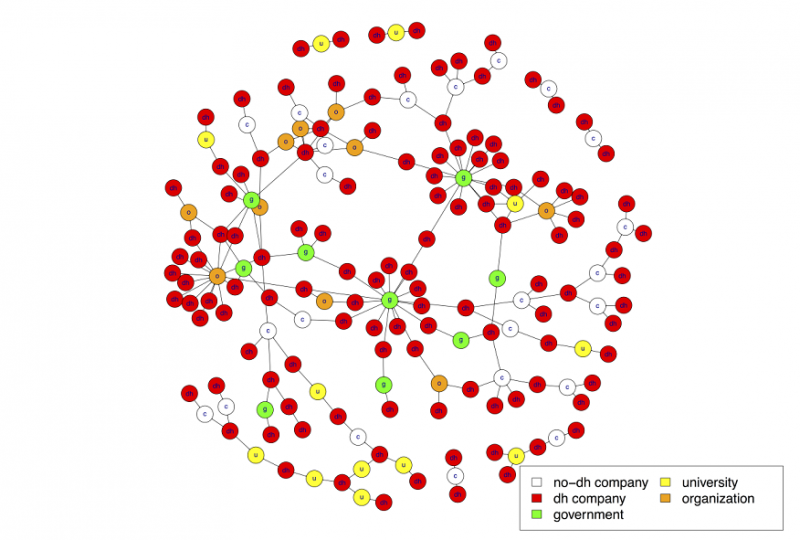
In poche parole, per svolgere il nostro lavoro di mappatura (e rispettare i termini del bando del BIS) abbiamo dovuto trovare delle alternative. Alternative efficienti, sia chiaro. Che non fossero quelle di chiedere a una squadra di stagisti di setacciare il web per settimane e settimane alla ricerca di ogni azienda che potesse far parte di questo o quel distretto. E proprio il metodo è un forte elemento di novità del report. Che è stato realizzato combinando le tradizionali metodologie qualitative (in primo luogo le interviste agli stakeholder più rilevanti), con un innovativo approccio data-driven, basato sulle tecnologie di acquisizione di dati sul web sviluppate da SpazioDati (e a fondamento di Atoka, il nostro tool di sales intelligence e lead generation).
Naturalmente mi rendo conto che tale approccio può sembrare eterodosso, ma oltre a essere nuovo, è anche efficiente. Anzi, non credo di commettere chissà quale spoiler se vi dico subito che il committente è rimasto impressionato per la qualità e la quantità dei risultati, e soprattutto per la rapidità con cui si è giunti alla mappatura. Per farla breve, noi e NIESR abbiamo usato algoritmi di raggruppamento basati sulla densità, con l’obiettivo di identificare i modelli di agglomerazione geografica delle aziende. In questo senso, l’analisi quantitativa rappresenta una netta cesura con i vecchi metodi.
Infatti usando i dati raccolti sul web per identificare le aziende appartenenti a ciascun settore, abbiamo potuto fare a meno dei troppo generici SIC, includendo nello stesso settore aziende con SIC anche lontanissimi tra loro. Inoltre, usando un algoritmo in grado di identificare i distretti sulla base della distanza fisica tra le aziende abbiamo potuto identificare i distretti sparsi su più aree amministrative discrete. Ancora, esaminando i link presenti nelle pagine web delle aziende abbiamo potuto analizzare le relazioni interaziendali, e tra aziende e altre istituzioni.
L’analisi quantitativa si è dunque sviluppata in 5 fasi:
1) Selezione del campione
2) Raccolta dei dati
3) Classificazione delle aziende
4) Identificazione dei cluster geografici
5) Analisi dei link
Come punto di partenza abbiamo selezionato un set di aziende e abbiamo raccolto dati testuali non strutturati dai loro siti web usando i tool proprietari di SpazioDati. Questi dati sono stati quindi utilizzati per calcolare degli indicatori quantitativi in grado di stabilire quali aziende appartenessero realmente al settore di interesse. Abbiamo poi usato, come accennato anche sopra, un algoritmo di raggruppamento basato sulla densità per identificare le concentrazioni di aziende dal punto di vista geografico. Per concludere, abbiamo esaminato le reti di relazioni generate dai link nei siti web.
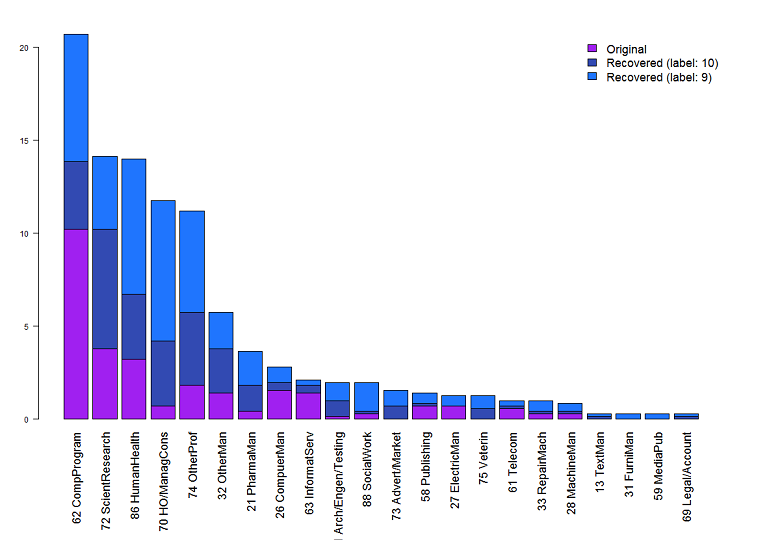
Come dicevo all’inizio del post, un solo SIC non può catturare tutte le aziende attive nel settore della sanità digitale. E infatti la figura sotto mostra che gran parte delle aziende trovate dai nostri algoritmi rientrano in 5 settori SIC: programmazione informatica (SIC 62), ricerca scientifica (SIC 72), sanità (SIC 86), attività di consulenza a livello direttivo e gestionale (SIC 70), altri servizi professionali (SIC 74). Mentre i primi tre codici SIC sono molto coerenti con la definizione della sanità digitale come settore all’intersezione tra la tecnologie e le attività sanitarie, gli ultimi due codici no.
Per farla breve, il risultato dei nostri sforzi (sulla sanità digitale) è stato questo:
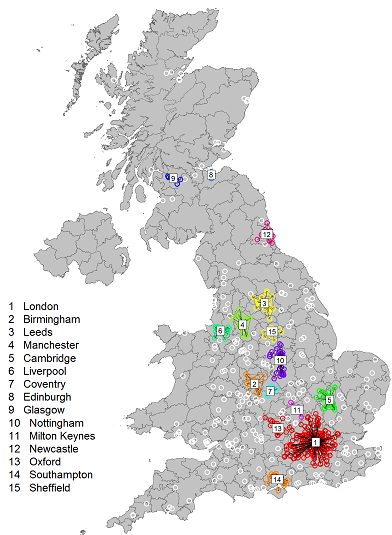
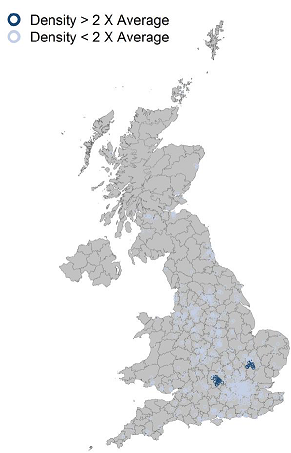
La mappa suggerisce che le maggiori aree di concentrazione del settore sono vicino a Londra (ad esempio Oxford, Cambridge, Southampton), o si trovano lungo un corridoio sud-nord che corre da Birmingham a Leeds. Nel nord del Regno sono le zone di Newcastle, Edimburgo e Glasgow a ospitare dei cluster più isolati e relativamente più piccoli. Se però applichiamo un filtro, e selezioniamo solo i cluster con una densità di aziende del settore doppia rispetto alla media nazionale, allora le cose cambiano, e spiccano solo Oxford e Cambridge.
Insomma, un approccio vincente che ci ha consentito di arrivare a risultati cospicui. Ed è solo l’inizio… con la potenza degli algoritmi si può davvero mappare quello che un tempo si pensava “immappabile”.
Non è tutto: oltre alla possibilità di esplorare territori destrutturati da un punto di vista concettuale, o fenomeni emergenti non censibili con le classificazioni ordinarie, questo tipo di analisi ha tempi molto rapidi rispetto alle metodologie tradizionali (anche se l’integrazione tra i due approcci è estremamente facile). E un grande vantaggio è la possibilità di offrire indicazioni preziose su temi di frontiera ancora poco conosciuti, per esempio ai decision makers che devono elaborare politiche di indirizzo o strategie industriali.
La foto in copertina è di 0x010C (wikipedia.og). Michele Barbera, autore di quest’articolo, è il CEO di SpazioDati.
Devi fare login per commentare
Accedi